AI-Demo AI-Training
Introduction
There are two ways to interact with the exhibit. Either you train an AI by driving a simulated car yourself, or you compile a data set from several drives already completed by other visitors. In both cases, an AI is trained with generated or selected data. If you use existing data for training, you first filter it by certain criteria (KPIs - Key Performance Identifier), such as driving safety and speed. Afterwards, one can observe how the just trained AI drives on the track and compare whether it can achieve similar KPIs as the training data or whether you can recognize your own driving style. To hightlight the use of an actual AI rather than just replaying control data, the AI's track is different form the training track.
Training track:

AI test track:

Data collection

During the training drive, the human generates the control commands (steering angle, throttle, brake) and the simulated environment provides us with sensor values. The car is equipped with several distance sensors that measure the distances to the nearest objects in different directions. A Hall sensor is used for the vehicle speed calculation. Data is recorded at a rate of 50 Hz and ultimately results in a training data set for the AI. The sampling rate of 50 Hz is only a rough selection, which can of course vary depending on the desired level of resolution and compute capacity.
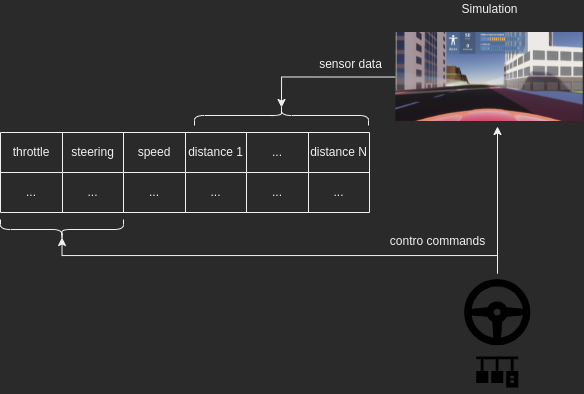
Training
For our AI we chose a regression method called Random Forest as it's "brain". This method offers many advantages, such as short training time and fast evaluation.
For the training, the data are divided into so-called inputs (X) and responses (Y). In our case, the responses are the control commands (throttle and steering) and the inputs are all sensor data (speed and distances).
The implementation of the training process in Python with the sklearn and pandas frameworks is trivial. It could look similar to the following code:
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
...
# prepare data
data = pd.read_csv("training_data.csv")
data = data.drop_duplicates()
data = data.replace([np.inf, -np.inf], np.nan).dropna(axis=0)
data = data[(data.T != 0).any()]
Y = data["throttle", "steering"].copy()
X = data.drop("throttle", "steering", axis=1)
# initialize Regressor
model = RandomForestRegressor(...)
# train
model.fit(X, Y)
...